 腾讯登录
腾讯登录《转》访中科院方向东教授:精准医学“两张皮”--生命组学数据与医疗大数据的规范与整合
| 导读 | 《转》访是转化医学网的品牌专访栏目,是业内专家、大佬、知名企业智慧交流碰撞的平台,也是促进行业健康发展的重要力量,《转》访致力于打造转化医学领域最知名的专家访谈栏目。 |
“精准医学”的开展,是以多组学大数据为基础,结合患者临床医疗与健康数据,实现精准的疾病分类及诊断、个性化的疾病预防和治疗。如何有效集成、整合、分析不同来源、不同层次的多组学大数据,如何规范和标准化医疗大数据,使两部分数据能有机融合,是急需解决的科学问题。近期,我们有幸采访到中科院北京基因组研究所“百人计划”研究员,方向东教授。
目前方教授主持负责的课题:精准医学大数据处理和利用的标准化技术体系建设正在开展。这是2016年国家启动的”精准医学研究”重点专项三大数据项目之一,另外两个项目:精准医学大数据管理和共享技术平台建设、疾病研究精准医学知识库构建,分别由军事医学科学院和复旦大学牵头承担。三个项目同时启动,共同推进我国精准医学大数据行业建设。
转化医学网:方教授,您好!您是何时开始大数据研究的?关于大数据在生命科学中的应用,请简单介绍一下?
方教授:2003年以后,特别是人类基因组计划完成以后,高通量组学技术开始快速发展。大规模测序成为可能,改变了原本做PCR、分子杂交等的一次只能研究一个基因的效率,实现了一次测序反应可以同时获得数十万至数十亿条DNA片段上碱基信息,产生了大量的生命组学数据。
我最初学临床医学出身,2007年开始接触到组学和大数据后,发现它的研究思路与传统医学思维不同,后者通常先假设病因,通过一系列实验来验证病因。而前者是通过测序来筛选变异,直接锁定相关致病基因。
举一个乳腺癌患者变异基因筛选的例子,找一组临床正常人群(自然人),和一组乳腺癌患者,首先比较他们在一个群体中哪些是共性基因:正常人携带的遗传标准是什么样的,肿瘤患者的遗传标准是什么样的。再比较两组的差异,比较得出在肿瘤患者中携带概率比较高的位点,这样筛选出的变异信息可以进一步判断病因。
另外在非编码区,我们说的单核苷酸多态性的变化:一个碱基发生了改变,一个C(胞嘧啶)后来变成了A(腺嘌呤),它可能和得肺癌是相关的。在检测时可以把这个位点检测出来,但得出这个结论,需要大人群、大样本的队列研究。另外需要大数据分析:不是一段或几个核苷酸的,而是一个人全部的30亿个碱基。通过大数据分析,得出的结论,可以用于临床上准确诊断,作为早期防治的依据。
通过大数据分析,获得临床上以前不能准确获知的信息。得到相对准确,反应临床治疗效果,早期诊断的依据,这是大数据最主要的应用方式。
在药物研发方面,以前药物研发周期很长,投入经费多,因为要一个个试,现在通过用测序的方法可以检测出药物的细胞学反应,以及对细胞表型和功能的影响,进而可以一次删、筛选很多前体化合物。
大数据研究不是不做功能,生物学功能依然是科学问题的重要导向。
转化医学网:基于目前的生命组学数据未能有效用于临床,怎样做到改进和加强?
方教授:这就是我提出的精准医学面临“两张皮”的问题,这是一个非常严峻的局面。首先,临床每天产生各种类型的医疗大数据:病历、处方、生化检测、影像报告等等,种类繁杂,而且很多是非结构化的,不能形成系统化的电子信息。如何把非结构化数据统一标准,变成结构化的电子化的信息,这是临床做医学大数据重点要突破的瓶颈技术。所以现在要建立EMR电子健康档案系统,通过模式识别和语义分析等手段将各种不同类型的媒体信息变成计算机可识别的信息,以便于后续与生命组学数据进行整合分析。
而生命组学数据指高通量方式产生的基因组,转录组,表观组,蛋白组的各种组学大数据,这种数据绝大多数通过测序平台获取。做基础科研的人,产生很多生命组学数据,这里面蕴含和临床表型的关联信息,但还没有标准和规范,临床医生要么看不懂,要么没办法马上应用到临床预防,诊治环节。
另一方面我们写了很多文章,又不能和临床产生的生化指标信息有效整合,变成新的治疗方式或药物。
这就是“两张皮”,我们后面做的工作就是希望生命组学分析的时候不要空中楼阁、只是发表SCI论文,而是针对临床上遇到的问题,无论是预防还是治疗,给他们提供更有意义、更有针对性的建议。
目前精准医学最需要做的事情,是将这两张皮合到一起,使这两部分数据得以有效关联和融合,这种现象可望在未来几年尽快得到改善,要不然都是自说自话。
转化医学网:请展开讲讲这两种数据的整合方式?
方教授:我们举例来说明如何用生命组学的数据解读临床的问题。一位患者,主诉:胸痛,有咳血。临床检测一系列病理指标:影像学的照胸片、CT、做PET,痰培养,支气管镜等。同时给他做基因组测序。
人类将近2万的基因,其中检测到表达有变化的可能有4~5000个,但并非都和咳血有关系,因为有些是从动效应。下面我们进一步做生物信息学分析,简化来说就是对检测数据进行整合,标化,降维,功能注释,最终找到信号通路,同临床关联(前提是所有的临床数据变成电子化的信息)。其中找到最主要的矛盾,30个基因,可能和咳血是相关的。
这里面有很多比较专业的概念,比如:数据的维度:是指基于同一个人的样本,在不同层次上对其分析:DNA-基因水平、RNA-转录形成的产物、蛋白质-翻译后的产物进行分析,产生多维的数据。大方向上来说就是:基因组,转录组,表观组,这几个层面的分析。
不同的维度,同一个样本,会产生多种数据。所以第一步要把数据综合在一起进行分类,不同的数据有不同的标准。通过多组学数据来标化,仿真模拟的手段来筛选到最佳的靶点,这是最主要的。
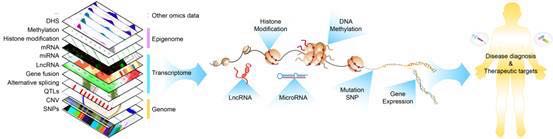
图片来源于方向东教授文章(遗传, 2015; 37(7): 655-663)
降维:样本的属性很多,维度很高。我们通过数学模型和统计学模型,通过聚类和功能注释的方式,将基因的突变、表达的变化、表观修饰变化等转化成疾病亚型等信息。如下图:通过两步降维,最初的五万多个变量,变成了37个,就比较集中。
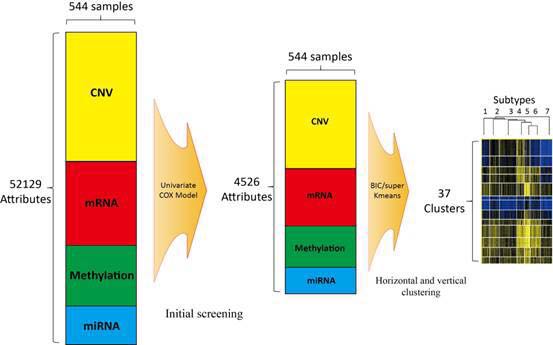
图片来源于参考文献(Cell Reports 2013; 4(3): 542-553)
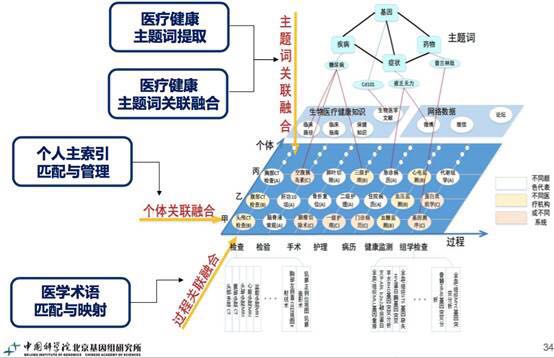
同临床信息的关联:组学数据同临床信息进行关联,前提是把所有这些临床数据变成电子化信息。然后从医疗健康领域把主题词提出来,通过主题词关联,或通过个体关联,或通过过程关联(医学术语匹配)几种方式进行关联,这是临床信息研究几个主要过程。接下来临床信息也要建模:分层建模(复杂信息建模的主要方法),再同组学数据进行匹配关联。
转化医学网:我们大数据行业存在哪些困难问题,以及您有哪些改进的建议?
方教授:大数据行业的建设,在基础研究方面,需要尽快建立符合精准医学需求的大型队列、中国人遗传特征等大数据,特定疾病的大数据等等;临床上,建立临床信息规范化的电子病历。其次,数据必须真实可靠,因为不可靠的数据无法支撑研究甚至误导研究结果。
现在急需解决的是数据的规范标准。健康大数据另外还有两大瓶颈:隐私的问题、信息安全的问题,这是健康大数据工作两大伦理和法律层面的问题,需要政策层面给予支持和优化,建立完善的法律法规和标准。
以上就是我们思考的需要改进的问题,希望我们这几年能努力推动。
后记:在方教授的办公室,看到北京基因组所主编的《精准医学》国家出版工程系列图书的两本分册《基因组学》和《转录组学》,将作为提供给临床科研工作者的参考教科书。正如方教授所说:“先把专业和团体的标准建立起来,下一步推进医疗卫生的行业标准,最终包括测序、如何挖掘数据规范,建立国家标准。这样大家的工作就有了客观的依据,就按照标准来做。”相信通过行业规范的建设,通过政府,企业和金融机构的积极参与,适合我国国情的精准医学体系能很快进入具体实施阶段。
方向东

中国科学院北京基因组研究所“百人计划”研究员、第一军医大学临床医学本科、免疫学硕士、人体解剖学和组织胚胎学博士。曾为美国华盛顿大学医学院医学遗传系助理教授。
现担任国家“十三五”重点研发计划“精准医学研究”重点专项项目《精准医学大数据处理和利用的标准化技术体系建设》的首席科学家。还担任中国转化医学联盟理事、国家科学技术部“人类遗传资源管理”专家、国家卫生计生委临床遗传专科委员会和中国遗传学会遗传咨询分会专家委员;人民卫生出版社系列期刊管理委员会和中国医药生物技术协会生物医学信息技术专业委员会常务委员;中国卫生信息学会健康医疗大数据政府决策支持与标准化、中国医药生物技术协会生物诊断技术、中国生物工程学会计算生物学与生物信息学、中国生理学会血液生理等专业委员会委员。还是《发育医学电子杂志》主编、Genomics Proteomics Bioinformatics副主编、《遗传》杂志编委。
从事医学遗传学、基因组学和转化医学研究20余年带领研究组整合分析多组学数据,筛选遗传性血液病、肿瘤等疾病的诊疗靶点,为临床制定更加高效、特异的干预策略提供理论基础和实验依据。作为通信和第一作者发表SCI论文30余篇;申请国家发明专利10项,授权5项;获得新药证书1项。
END
(转化医学网360zhyx.com)
还没有人评论,赶快抢个沙发