 腾讯登录
腾讯登录从双螺旋到国家基因库
| 导读 | 现代分子生物学发展七十年来成果揭示,生命体由蛋白质行使基本功能,负责呼吸、进食、排泄废物、生殖等活动,而蛋白的表达由基因进行编码调控,作为遗传物质的DNA被称为生命的蓝图。 |
现代分子生物学发展七十年来成果揭示,生命体由蛋白质行使基本功能,负责呼吸、进食、排泄废物、生殖等活动,而蛋白的表达由基因进行编码调控,作为遗传物质的DNA被称为生命的蓝图。

分子生物学的中心法则
基因双螺旋结构的发现历史
1953年沃森(James Watson)和克里克(Francis Crick)在Nature杂志上发表了DNA双螺旋结构的论文,并在1962年获得了诺贝尔医学奖,被认为是现代科学发展史上一个重要的里程碑。
DNA双螺旋结构的发现开启了科学家们在分子水平上对生命现象进行探索,距今短短六十多年,但是已经超越我们过去所有时间对生命分子学水平上的认识。
沃森生于美国芝加哥,在芝加哥大学获得了学士学位,并在印第安纳大学进行博士研究。1951年,当他在一次意大利举行的学术会议上听到关于DNA结构的研究报告时,他被强烈地吸引,毅然决定从美国前往位于英国剑桥著名的卡文迪什实验室进行DNA分子结构的研究。在这里他遇到了正在准备博士论文的克里克, 两个人在研究方向上一拍即合,不久后便提出DNA双螺旋的结构模型并发表。
值得一提的是,那年沃森才25岁。

沃森和克里克
有趣的是在地球的另一端,对生命起源DNA结构的暗示在很早之前便出现在中国。 在华夏文明中,伏羲、女娲被认为是传说中的天神以及人类的祖先。女娲以泥土造人,炼五色石补苍天;伏羲教人们结绳记事,结网捕鱼,驯养动物。
1967年吐鲁番的夫妻合葬墓群中出土了伏羲女娲图,该图中伏羲在左女娲在右,人首龙身,龙尾交缠代表了生命的起源。二人上方有以象征太阳的圆轮,尾下有象征月亮的半月;我国古代有“天圆地方”之说,因此女娲手执圆规象征天,伏羲手执方矩象征地。
这一神秘图像竟与沃森和克里克提出的DNA双螺旋结构惊人地相似,该图引起了国际上的关注,在1983年成为联合国教科文组织杂志的首页插图。

伏羲女娲图
基因测序的发展简史
DNA负责了我们的遗传信息,但其组成只使用了四个简单的字母,即代表四种不同碱基的A/T/G/C.
碱基的排列顺序成了我们了解生命活动而必须破译的遗传密码。上个世纪八十年代,美国政府领头发起了对人类基因组进行测序的工作,被称为人类基因组计划(Human Genome Project),其与曼哈顿原子弹计划、阿波罗登月计划并列为二十世纪三大科学计划。
该计划在1984年进行了首次讨论,并于1990年在美国正式启动,当时预计以1美元1个碱基的成本测出人类约30亿碱基,预期耗时15年。
随后该计划逐渐扩展为国际合作计划,英、日、法、德、中、印先后加入,我国的人类基因组计划于1994年启动,在1999年正式确定北京华大基因研究中心牵头负责该项目1%的基因测序工作。
随着测序技术的不断成熟,测序时间及成本一直在不断地降低,最终在2000年6月宣布人类基因组测序的原始草图完成,比预计的2005年完成提前了5年。 提前完成的实现得益于测序仪器及技术的持续发展。在沃森和克里克提出DNA双螺旋模型的时候,测序技术还没有发展起来。
直到1977年左右弗雷德里克·桑格(Frederick Sanger)才应用一种链终止法使测序工作得以实现, 并在相当长的时间内成为最普遍的DNA测序技术,被称为桑格测序。
桑格于1918年出生在英国,他父亲是一名医生,他自己本身对生物化学感兴趣而拿到了剑桥大学的博士学位,当桑格测序问世的时候,他已经59岁了。
桑格测序的诞生是人类基因组计划得以展开的重要关键之一,他本人也因此技术于1980年获得了诺贝尔化学奖。直到今天,一代测序还是目前所有基因检测的国际金标准。

弗雷德里克·桑格
二代测序诞生在2005年左右,被称为“Next-generation sequencing”技术,简称NGS.
二代测序以低廉的价格,可同时对几十万至几百万条DNA分子进行快速测序分析的特点又被称高通量测序技术。到了2007年,用二代测序再一次完成一个完整的人类基因组序列图谱只花费了150万美元,耗时3个月。比起用一代测序完成的人类基因组计划,其大大降低了测序的成本和时间。
2011年以来,三代测序也逐渐开始发展起来,三代测序进一步加快了测序的速度,使实时获取序列变得更加容易,今天人类基因组测序只需要不到1万元,3天时间内即可完成。
基因信息的解读
随着测序技术的复杂性增加,测序文件数据量越来越大,因此涉及到后续生物信息处理难度也逐渐提高。得到了这些基因数据后,怎样才能更好地获取其中的信息?这逐渐成为基因测序后的重点和难点部分。 在2001年人类基因组测序完成的时候,人们发现人类细胞中98%以上的DNA都不编码任何蛋白,一度被划入了垃圾的行列,被称为“垃圾DNA”。
就编码蛋白的基因数量上而言,人体和蠕虫一样只具有约约20000个。大部分蠕虫的基因跟人类基因可以直接等效,而唯一的区别是,人类的垃圾DNA区域比例更大,也就是说一个生命体越复杂,垃圾DNA所占的百分比就越高。 科学家们开始质疑,为什么我们的遗传物质需要存储那么多无效的DNA?
如果不到2%的DNA是重要的,为什么进化的时候保持那些98%的无功能垃圾?相当于在细胞复制的时候,每复制一个有功能的碱基对的同时,就要使用大量资源复制另外49个“无用”的碱基,就像一个公司100个人里只有2个人干活,为什么我们还需要养剩下的98个人?似乎也过于浪费了一点。 随着研究进展科学家们逐渐发现,我们的基因组始终处于环境中各种潜在的破坏刺激下,如阳光中的紫外线辐射和食物中的致癌物质,这些对于我们基因组的完整性都是潜在的威胁。
如果我们的基因组会不断受到攻击,当50个碱基对中只有一个对编码蛋白序列非常重要,那么一个破坏性刺激能够击中要害的概率也就只有五十分之一。
由于蠕虫和酵母这类简单物种的生命周期很短,可以产生很多后代,因此则没有必要投入大量的精力来保护编码蛋白基因,他们的后代即使携带了突变而导致不能适应环境,但大部分后代仍能够存活。
而人类需要很长时间才能产生很少量的后代,因此我们需要足够比例的“垃圾DNA”来确保我们的遗传信息能尽可能完好地传给后代,而不会因为基因突变而导致后代无法存活。
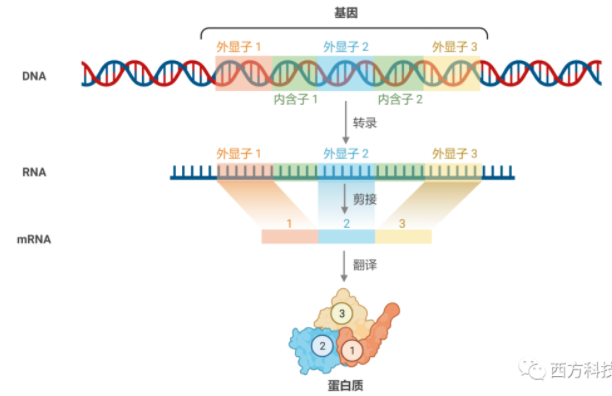
基因通常是DNA间的一段序列;基因中被插入各种内含子,转录成RNA后只有外显子才被翻译为蛋白质。大约只有2%的DNA编码蛋白质。
得到测序的结果后,为了更准确地解读其中的遗传信息,首先需要丰富的数据资源。就好像知道了一个英语单词,需要在英语词典中知道具体单词的释义,基因数据库就是这样的词典。
基因数据库不仅仅包括基因数据,还包括相对应的临床数据,即该基因表型相对应的遗传特征、患病概率、药物治疗适应症等。当我们建立了大规模的基因组数据库和知识库后,就可以将基因变异信息、疾病临床表型、诊疗方案等数据结合起来,从而建立特定基因与疾病的关联。 目前世界上应用最广泛的数据库是成立于1988年的美国国家生物技术中心(National Center for Biotechnology Information),简称NCBI. 其次是1994年成立与英国剑桥的欧洲生物信息研究所(European Bioinformatics Institute), 以及日本DNA数据库(DNA data bank of Japan)。
虽然美国是基因测序技术的发祥地,但是由于人口基数和不断递增的医疗需求,我国将成为全球最大的测序市场。2016年,我国筹建了国家基因库,位于深圳大鹏,与美国国家生物技术信息中心(NCBI)、欧洲分子生物学实验室(EBI)、日本DNA数据库(DDBJ) 等数据库进行交换和共享数据。

深圳国家基因库
有了数据库比对之后,基因检测的解读结果可以广泛应用于科研、药企、临床以及消费者。 在临床中,基因测序在无创产前筛查发展得较成熟,除此之外基因测序也逐渐应用到遗传性肿瘤筛查和肿瘤靶向治疗等方向。
其中遗传肿瘤筛查检测得较多的是乳腺癌和卵巢癌中BRCA基因突变;在肿瘤靶向治疗中,通过基因测序检测肺癌患者EGFR及HER蛋白是否突变扩增等信息,可以选择给患者更适合的肿瘤靶向药。 除开科研机构及临床病人的测序需求以外,目前针对消费者个人DNA信息咨询的服务也逐渐兴起。这种面向消费者的基因检测通过收取消费者的唾液,提取其中唾液上皮细胞里的DNA,可以大致分析出如祖源、营养代谢、健康风险等信息。
随着测序技术的普及以及大规模人群样本信息的收集,期待在不久的将来我们可见证到人人都有“基因身份证”的时代。
参考文献:
[1] Wikipedia. 人类基因组计划. 2021-5-1.
[2] Koonin EV, Galperin MY. Boston:Kluwer Academic; 2003. Chapter 4.
[3] 内莎 · 凯里. 垃圾DNA. 重庆出版社, 2017.


还没有人评论,赶快抢个沙发